Contexte
Un data pipeline qui scrape les communautés Reddit via une extension de navigateur, stocke les posts avec des vector embeddings, et fait remonter les pain points, les schémas comportementaux et les clusters de sujets grâce à une analyse par AI. Ce système a été utilisé pour orienter la direction produit de Lume.
Le problème
Avant de créer un produit pour une audience spécifique, il faut comprendre ses véritables difficultés, et non se baser sur des suppositions. Reddit est la source la plus riche pour identifier les problèmes des utilisateurs sans aucun filtre, en particulier pour notre niche de l'époque (le gaming), mais :
- Les posts sont noyés dans le bruit (mèmes, hors-sujets, contenu de faible qualité)
- La lecture manuelle ne passe pas à l'échelle au-delà de quelques centaines de posts
- L'API de Reddit a des rate limits stricts et n'expose pas tout ce qui est visible dans le navigateur
- Il est impossible de faire une recherche sémantique sur des milliers de posts pour trouver des tendances
J'avais besoin d'un moyen d'ingérer tout l'historique d'un subreddit, puis de l'interroger avec des questions comme "quelles sont les plus grandes difficultés des utilisateurs ?" ou "qu'est-ce qui déclenche une rechute ?" pour obtenir des réponses basées sur les données.
Ce que j'ai construit
Un système en trois parties : une extension de navigateur pour le scraping, Supabase + pgvector pour le stockage, et un dashboard Streamlit pour l'analyse par AI.
Extension de navigateur : Une Chrome extension qui fait défiler un subreddit, parse le DOM et exporte les posts avec tous les fils de commentaires imbriqués au format JSON. Elle fonctionne sur le nouveau Reddit (Shreddit), préserve la hiérarchie des réponses, filtre les publicités, gère les plages de dates et permet de reprendre le scraping. Le choix d'une Chrome extension s'explique par le fait que Reddit bannissait agressivement tout type d'automatisation.
Data pipeline : Des scripts d'importation aplatissent les commentaires imbriqués, font un upsert vers Supabase, puis génèrent des embeddings à 768 dimensions via Gemini pour chaque post et commentaire. Le traitement par lots avec un exponential backoff permet de gérer les rate limits sur des milliers d'éléments.
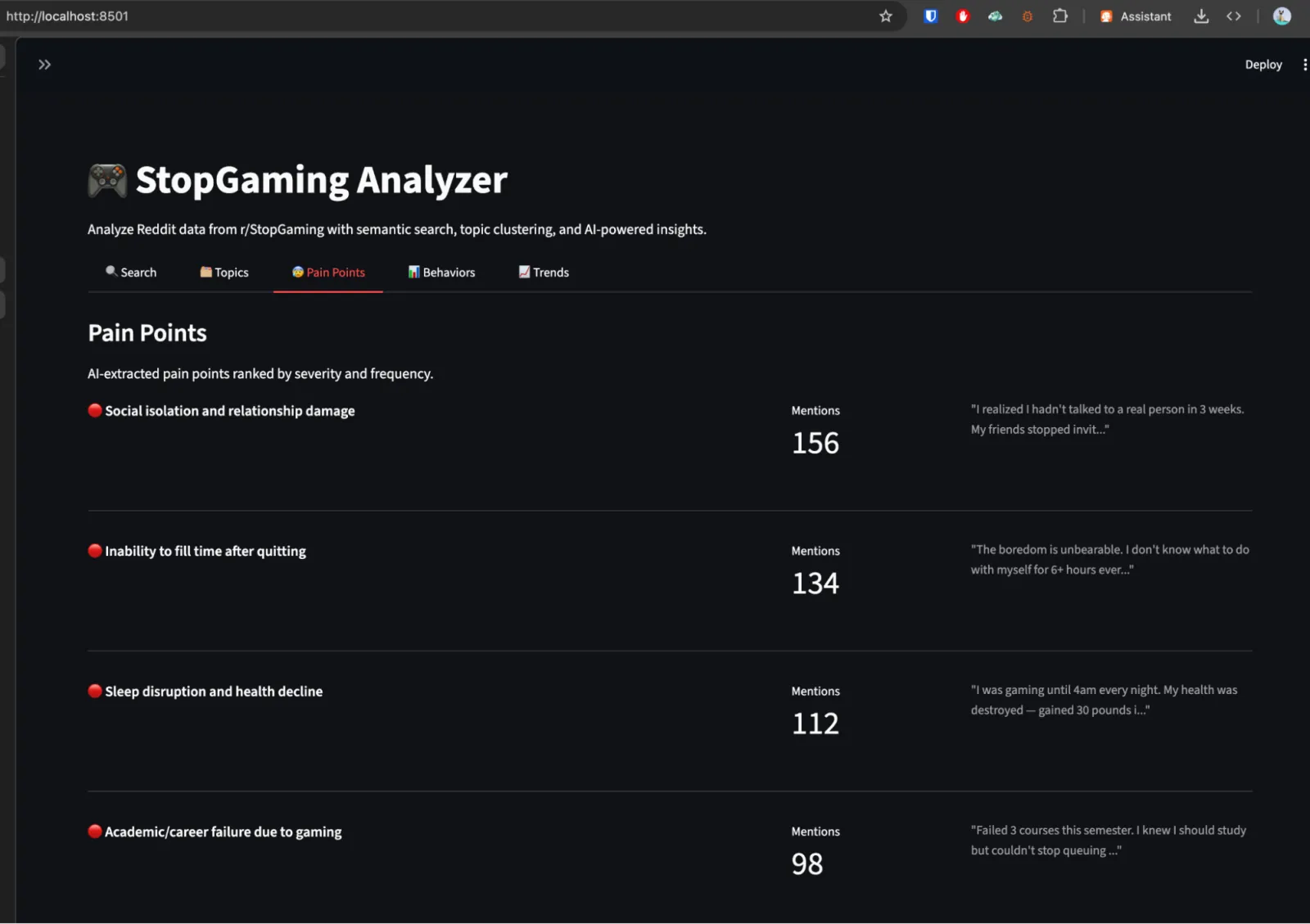
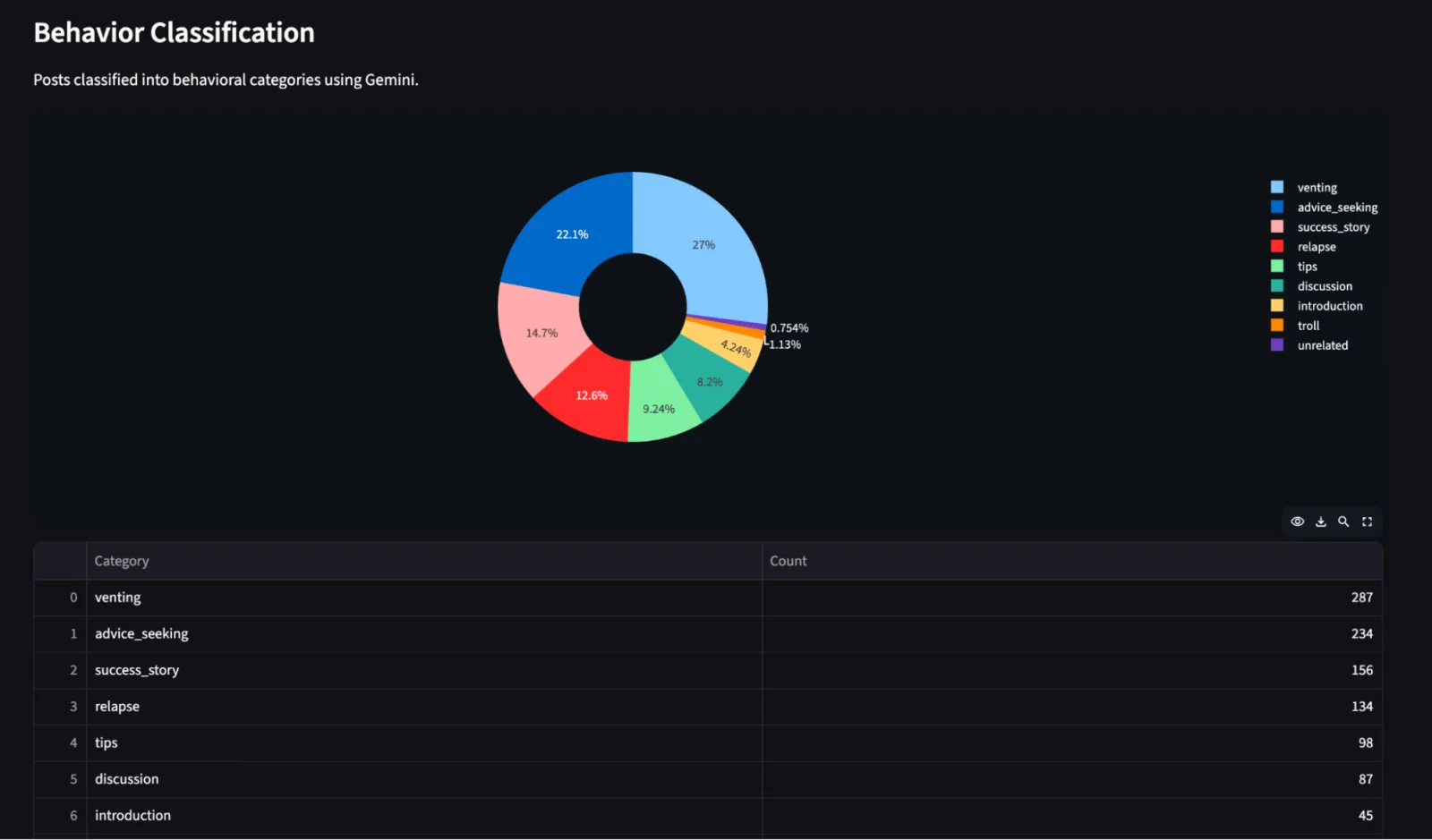
Dashboard d'analyse : Une application Streamlit avec 5 modes d'analyse : recherche sémantique (requêtes en langage naturel sur tous les posts et commentaires via la similarité pgvector), clusters de sujets (regroupement K-Means avec des labels générés par Gemini pour chaque cluster), pain points (difficultés extraites par l'AI et classées par sévérité, avec citations sources), classification des comportements (posts catégorisés en 9 types : défouloir, témoignages de réussite, recherche de conseils, rapports de rechute, etc.), et tendances (schémas d'activité, répartition des comportements dans le temps).
Comment cela a orienté Lume
J'ai scrapé r/StopGaming, soit environ ~1 000 posts et ~9 000 commentaires. L'extraction des pain points et le clustering de sujets ont révélé des tendances qui ont directement façonné les fonctionnalités et le positionnement de Lume. Au lieu de deviner ce dont l'audience avait besoin, j'avais des données montrant exactement de quoi ils parlaient, ce qui générait le plus d'engagement, et quels états émotionnels les poussaient à poster.
Ces données ont été utilisées uniquement pour la direction produit de Lume et n'ont jamais été consultées en dehors de cette application locale. Il s'agit d'histoires sensibles et personnelles de personnes partageant leurs addictions, il me semble donc important de le préciser.
Durée
2025
Stack technique
Responsabilités
- Chrome extension pour le scraping de Reddit
- Pipeline de vector embedding (Gemini + pgvector)
- Dashboard d'analyse basé sur l'AI
- Extraction des pain points et clustering