Context
A data pipeline that scrapes Reddit communities via browser extension, stores posts with vector embeddings, and surfaces pain points, behavioral patterns, and topic clusters through AI analysis, used to shape the product direction of Lume.
The Problem
Before building a product for a specific audience, you need to understand what they actually struggle with, not what you assume they struggle with. Reddit is the richest source of unfiltered user pain, especially for our niche at this time (gaming), but:
- Posts are buried in noise (memes, tangents, low-effort content)
- Manual reading doesn't scale past a few hundred posts
- Reddit's API has strict rate limits and doesn't expose everything visible in the browser
- You can't semantically search across thousands of posts to find patterns
I needed a way to ingest an entire subreddit's history, then query it with questions like "what do users struggle with most?" or "what triggers relapse?" and get data-backed answers.
What I Built
A three-part system: browser extension for scraping, Supabase + pgvector for storage, and a Streamlit dashboard for AI-powered analysis.
Browser Extension: A Chrome extension that scrolls through a subreddit, parses the DOM, and exports posts with full nested comment threads as JSON. Works on new Reddit (Shreddit), preserves reply hierarchy, filters ads, supports date ranges and resumes. The choice of a chrome extension was because Reddit aggressively banned any automation type.
Data Pipeline: Import scripts flatten nested comments, upsert to Supabase, then generate 768-dimensional embeddings via Gemini for every post and comment. Batch processing with exponential backoff handles rate limits across thousands of items.
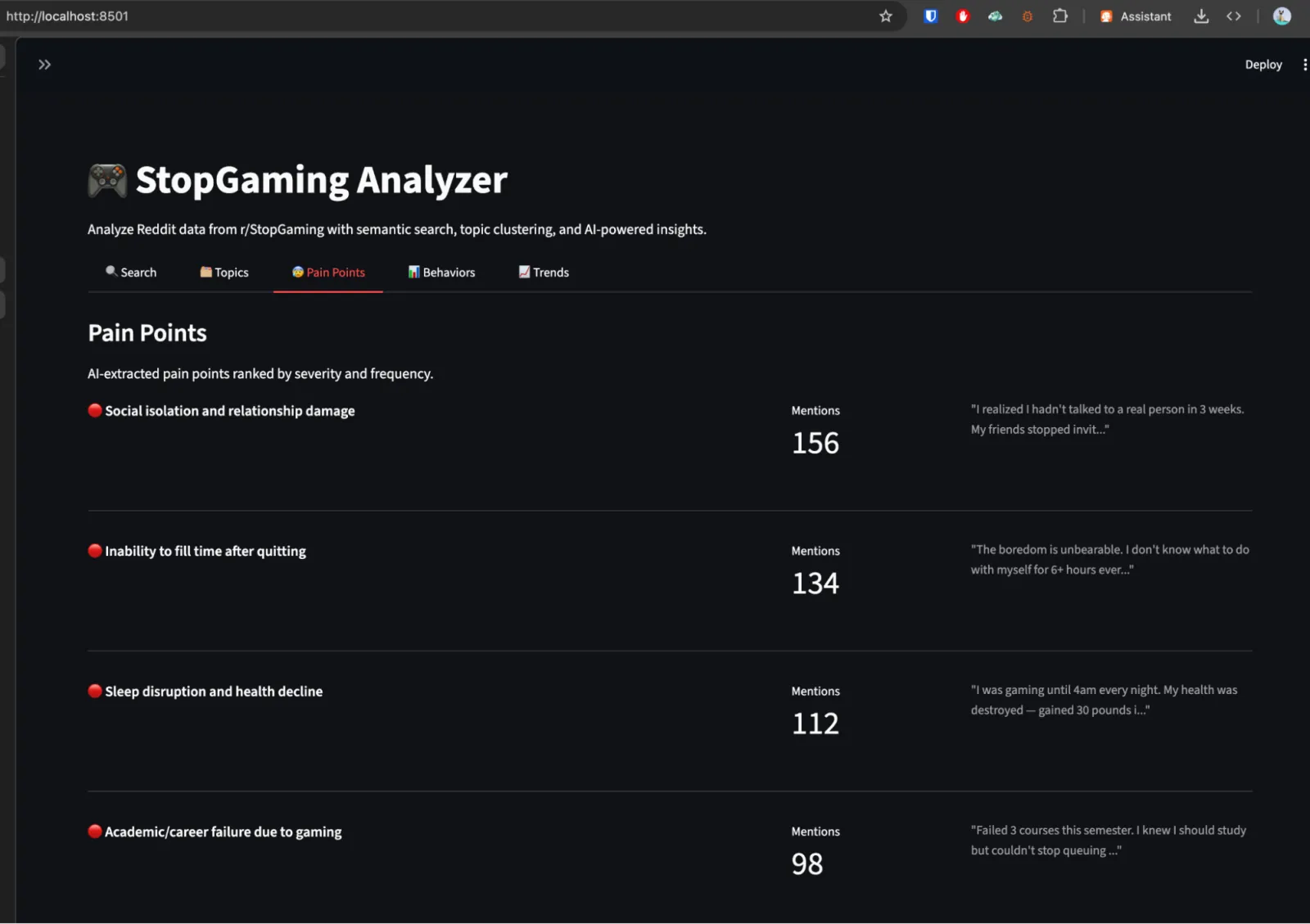
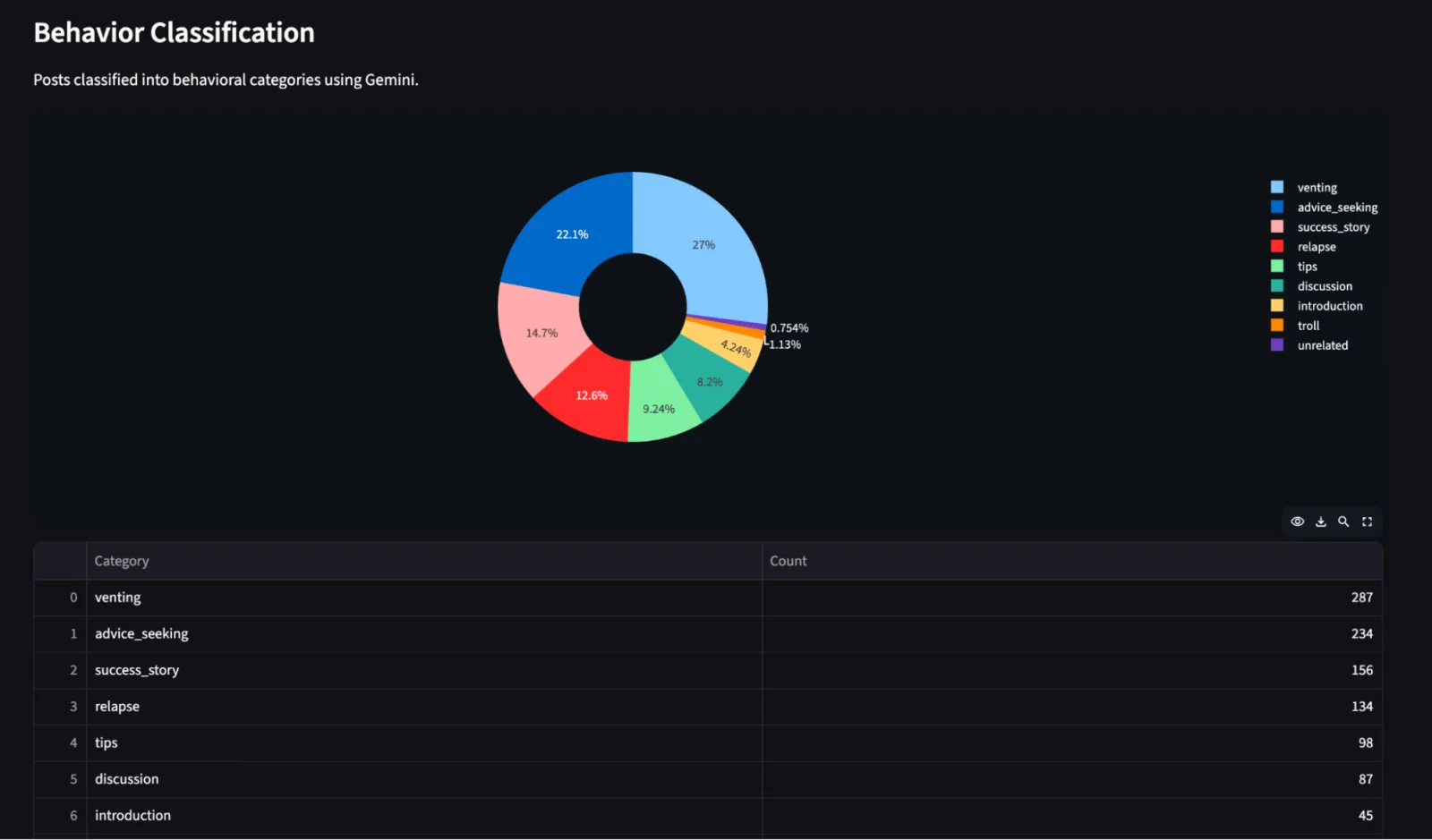
Analytics Dashboard: A Streamlit app with 5 analysis modes: semantic search (natural language queries against all posts/comments via pgvector similarity), topic clusters (K-Means grouping with Gemini-generated labels per cluster), pain points (AI-extracted struggles ranked by severity, with source quotes), behavior classification (posts categorized into 9 types: venting, success stories, advice-seeking, relapse reports, etc.), and trends (activity patterns, behavior distribution over time).
How It Informed Lume
I scraped r/StopGaming, ~1,000 posts, ~9,000 comments. The pain point extraction and topic clustering revealed patterns that directly shaped Lume's feature set and positioning. Instead of guessing what the audience needed, I had data showing exactly what they talked about, what got the most engagement, and what emotional states drove them to post.
This data has been used only for the product direction on Lume and has never been accessed out of this local app, this is sensitive and personal stories with people sharing about their addictions so I feel it's important to mention it.
Timeline
2025
Stack
Responsibilities
- Chrome extension for Reddit scraping
- Vector embedding pipeline (Gemini + pgvector)
- AI-powered analytics dashboard
- Pain point extraction and clustering