The Problem
A SaaS with 400 paying customers discovers churn only when the cancellation email arrives. By then it's too late. The signals were there weeks earlier: login frequency dropped, key features stopped being used, support tickets went unanswered. But nobody was watching.
The CS team checks dashboards manually once a week. Between checks, $15k+ in MRR quietly becomes at-risk without anyone noticing. By the time they reach out, the customer has already decided to leave.
The Solution
A daily monitoring pipeline that pulls subscription data from Stripe and product usage from PostHog, calculates a multi-signal risk score for every account, and triggers tiered interventions automatically: nudge emails for medium risk, personal outreach + Slack alerts for critical risk.
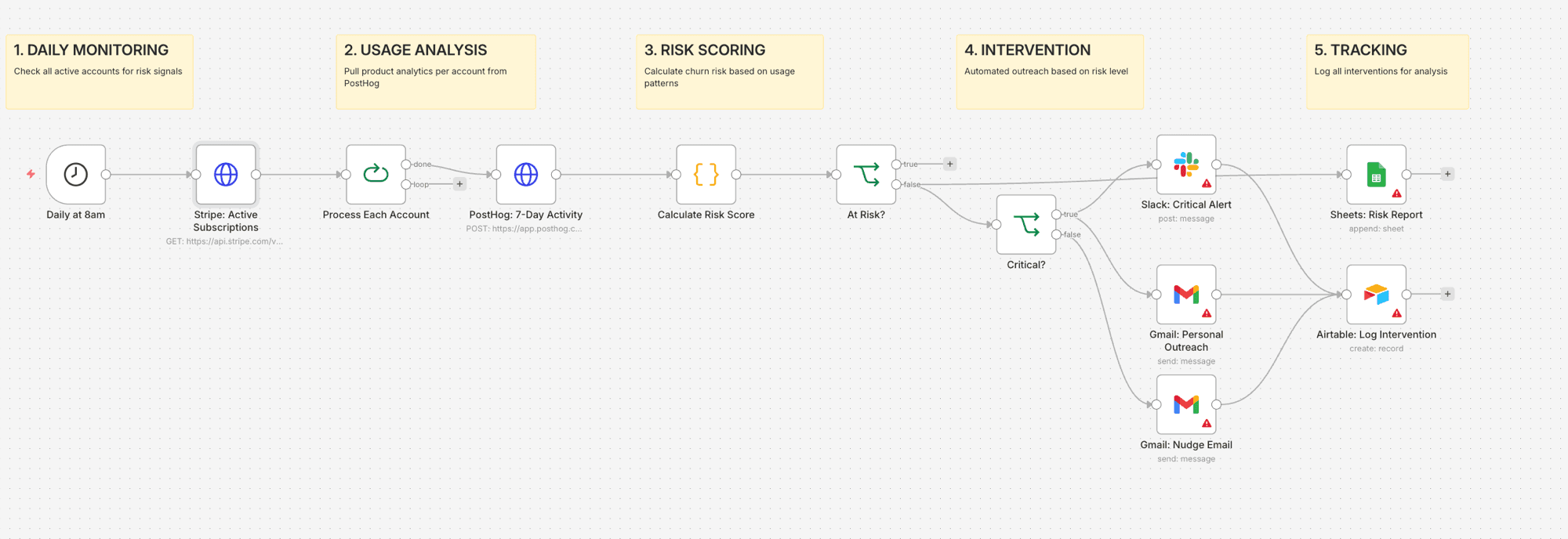
- Cron trigger fires daily at 8am
- Stripe API pulls all active subscriptions with payment status
- Split in Batches processes each account individually
- PostHog API queries 7-day event activity for that account
- Code node calculates risk score (0-100) based on usage drop, cancellation signals, payment issues, and plan type
- IF node filters: healthy accounts skip, at-risk accounts continue
- Second IF routes by severity: critical (score 50+) vs warning (25-49)
- Critical: Slack @channel alert to CS team + personal email from CS rep
- Warning: automated nudge email with feature tips and offer to help
- Airtable logs every intervention with timestamp, risk score, and action taken
- Google Sheets updates the daily risk report for trend analysis
Why I Built It This Way
The client originally asked for a simple "send an email when someone hasn't logged in for 7 days". But that's a lagging indicator. By the time someone stops logging in completely, they've already mentally churned. I pushed for a multi-signal approach because a single metric lies. Usage drop + payment failure + scheduled cancellation together tell a much more accurate story than any one signal alone.
The scoring algorithm uses weighted signals rather than hard thresholds. A user with zero activity for 7 days scores 40/100 on its own. But if that same user also has a scheduled cancellation (+35), they're at 75 (critical). Meanwhile, a user whose usage dropped 50% but is still paying and has no cancellation flag only scores 15 (warning). This tiered approach prevents alert fatigue while catching the accounts that truly need immediate attention.
I chose Split in Batches over processing all accounts in one pass because PostHog's API has rate limits. Processing one at a time with the batch node means the workflow handles 400 accounts as reliably as 40, with built-in retry logic. It's slower (takes ~5 minutes for 400 accounts) but never fails due to rate limiting.
The two-tier intervention (warning vs critical) exists because sending a "are you okay?" email to someone who just had a slow week is annoying and undermines trust. Warning-level accounts get a light-touch nudge ("here are features you haven't tried") that feels helpful, not desperate. Only critical accounts get the personal "we noticed you're less active" message. This distinction is what makes the system sustainable without burning customer goodwill.
The Workflow
This is a sanitized replica of the production workflow. Credentials, API keys, and client-specific data have been removed to protect confidentiality.
Results
- Churn rate reduced by 30% in the first quarter
- Average intervention happens 12 days before potential cancellation (vs 0 days before)
- CS team receives actionable alerts instead of checking dashboards manually
- $45k in MRR saved in the first 3 months from recovered accounts
- Full audit trail of every at-risk account and what action was taken
Timeline
2026
Stack
Responsibilities
- Multi-signal risk scoring algorithm
- Stripe + PostHog data aggregation
- Tiered intervention system
- Churn analytics dashboard