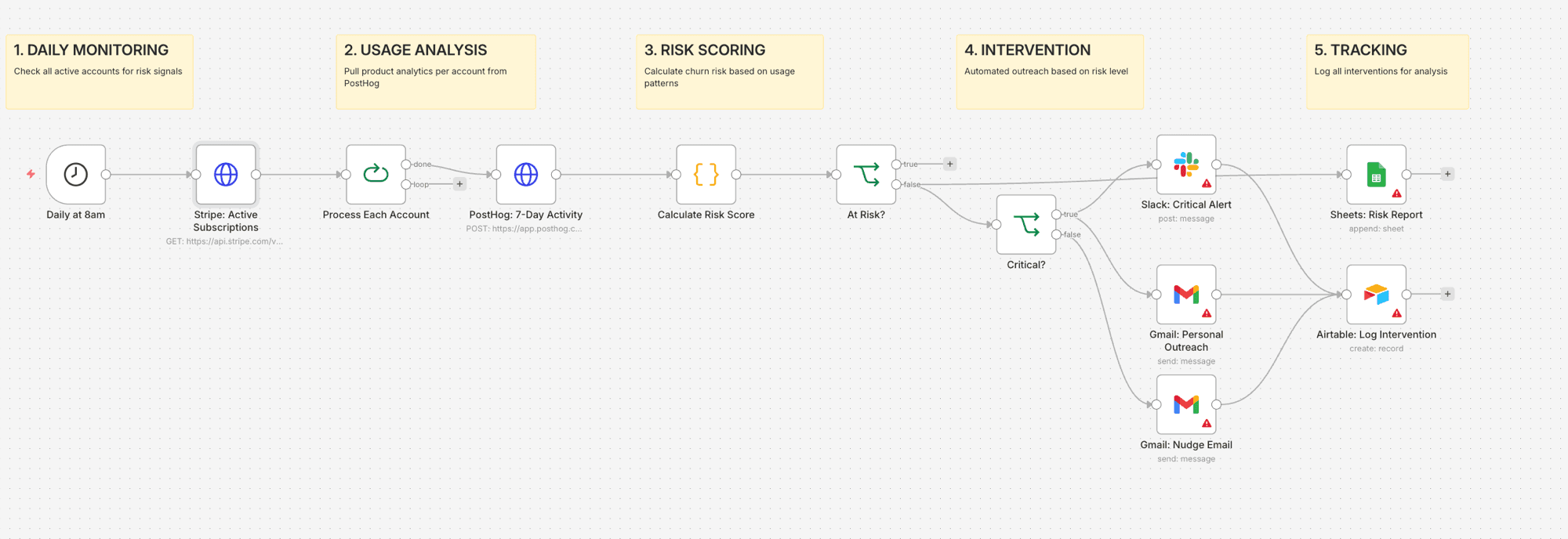
Le problème
Un SaaS avec 400 clients payants ne découvre le churn qu'à la réception de l'email d'annulation. À ce stade, il est trop tard. Les signaux étaient pourtant visibles des semaines plus tôt : baisse de la fréquence de connexion, abandon de fonctionnalités clés, tickets de support sans réponse. Personne ne surveillait.
La CS team consulte les dashboards manuellement une fois par semaine. Entre deux vérifications, plus de 15k$ de MRR deviennent silencieusement à risque sans que personne ne s'en aperçoive. Quand ils contactent enfin le client, la décision de partir est déjà prise.
La solution
Un pipeline de monitoring quotidien qui extrait les données d'abonnement de Stripe et l'usage produit de PostHog. Il calcule un score de risque multi-signaux pour chaque compte et déclenche des interventions automatiques : emails de relance pour les risques modérés, outreach personnalisé et alertes Slack pour les risques critiques.
- Cron trigger quotidien à 8h
- L'API Stripe récupère tous les abonnements actifs avec leur statut de paiement
- Split in Batches traite chaque compte individuellement
- L'API PostHog interroge l'activité sur les 7 derniers jours pour ce compte
- Le code node calcule un score de risque (0-100) basé sur la baisse d'usage, les signaux d'annulation, les problèmes de paiement et le type de plan
- Le node IF filtre : les comptes sains sont ignorés, les comptes à risque continuent
- Un second IF route selon la sévérité : critique (score 50+) vs avertissement (25-49)
- Critique : alerte Slack @channel pour la CS team + email personnalisé du chargé de compte
- Avertissement : email de relance automatisé avec conseils sur les fonctionnalités
- Airtable logue chaque intervention avec timestamp, score de risque et action effectuée
- Google Sheets met à jour le rapport de risque quotidien pour l'analyse des tendances
Pourquoi j'ai conçu le workflow ainsi
Le client voulait initialement un simple « envoyer un email si l'utilisateur ne s'est pas connecté depuis 7 jours ». C'est un indicateur retardé. Quand quelqu'un arrête totalement de se connecter, il a déjà churné mentalement. J'ai imposé une approche multi-signaux car une métrique isolée est trompeuse. La combinaison d'une baisse d'usage, d'un échec de paiement et d'une annulation programmée raconte une histoire bien plus précise.
L'algorithme de scoring utilise des signaux pondérés plutôt que des seuils fixes. Un utilisateur sans activité pendant 7 jours obtient 40/100. Mais si cet utilisateur a aussi une annulation programmée (+35), il passe à 75 (critique). À l'inverse, un utilisateur dont l'usage a baissé de 50% mais qui continue de payer sans flag d'annulation n'obtient que 15 (avertissement). Cette approche graduée évite la fatigue liée aux alertes tout en ciblant les comptes qui nécessitent une attention immédiate.
J'ai choisi Split in Batches plutôt qu'un traitement en une seule fois à cause des rate limits de l'API PostHog. Traiter un compte à la fois avec le node batch permet au workflow de gérer 400 comptes aussi facilement que 40, avec une logique de retry intégrée. C'est plus lent (environ 5 minutes pour 400 comptes) mais cela ne plante jamais à cause des limites d'API.
L'intervention à deux niveaux (avertissement vs critique) est nécessaire car envoyer un email « tout va bien ? » à quelqu'un qui a juste eu une semaine calme est agaçant et nuit à la confiance. Les comptes en avertissement reçoivent une approche légère (« voici des fonctionnalités que vous n'avez pas testées ») qui semble utile, pas désespérée. Seuls les comptes critiques reçoivent le message personnalisé « nous avons remarqué une baisse d'activité ». Cette distinction rend le système durable sans dégrader la relation client.
Le workflow
Ceci est une réplique assainie du workflow de production. Les identifiants, clés API et données clients ont été supprimés pour garantir la confidentialité.
Résultats
- Taux de churn réduit de 30% au premier trimestre
- Intervention moyenne effectuée 12 jours avant une annulation potentielle (contre 0 jour auparavant)
- La CS team reçoit des alertes actionnables au lieu de consulter des dashboards manuellement
- 45k$ de MRR sauvés en 3 mois grâce aux comptes récupérés
- Audit complet de chaque compte à risque et des actions entreprises
Durée
2026
Stack technique
Responsabilités
- Algorithme de scoring de risque multi-signaux
- Agrégation de données Stripe + PostHog
- Système d'intervention à plusieurs niveaux
- Dashboard d'analyse du churn