Le problème
L'équipe produit prend ses décisions à l'instinct car les données sont cloisonnées dans 4 systèmes distincts. PostHog suit les événements produit (rage clicks, feature requests, erreurs). Supabase stocke les tickets de support et les avis sur l'App Store. Une API interne personnalisée contient le backlog des feature requests avec le nombre de votes. Personne ne synthétise ces signaux pour obtenir une vision cohérente.
Chaque matin, le PM ouvre 4 onglets, parcourt les données brutes et tente d'identifier des tendances. Il manque le signal indiquant que 3 clients enterprise ont rencontré la même erreur sur la même page la veille. Il ne remarque pas que les plaintes sur le module "reporting" ont bondi de 400% cette semaine. Sans analyse structurée, c'est le client le plus bruyant qui dicte la priorisation, et non le problème le plus impactant.
La solution
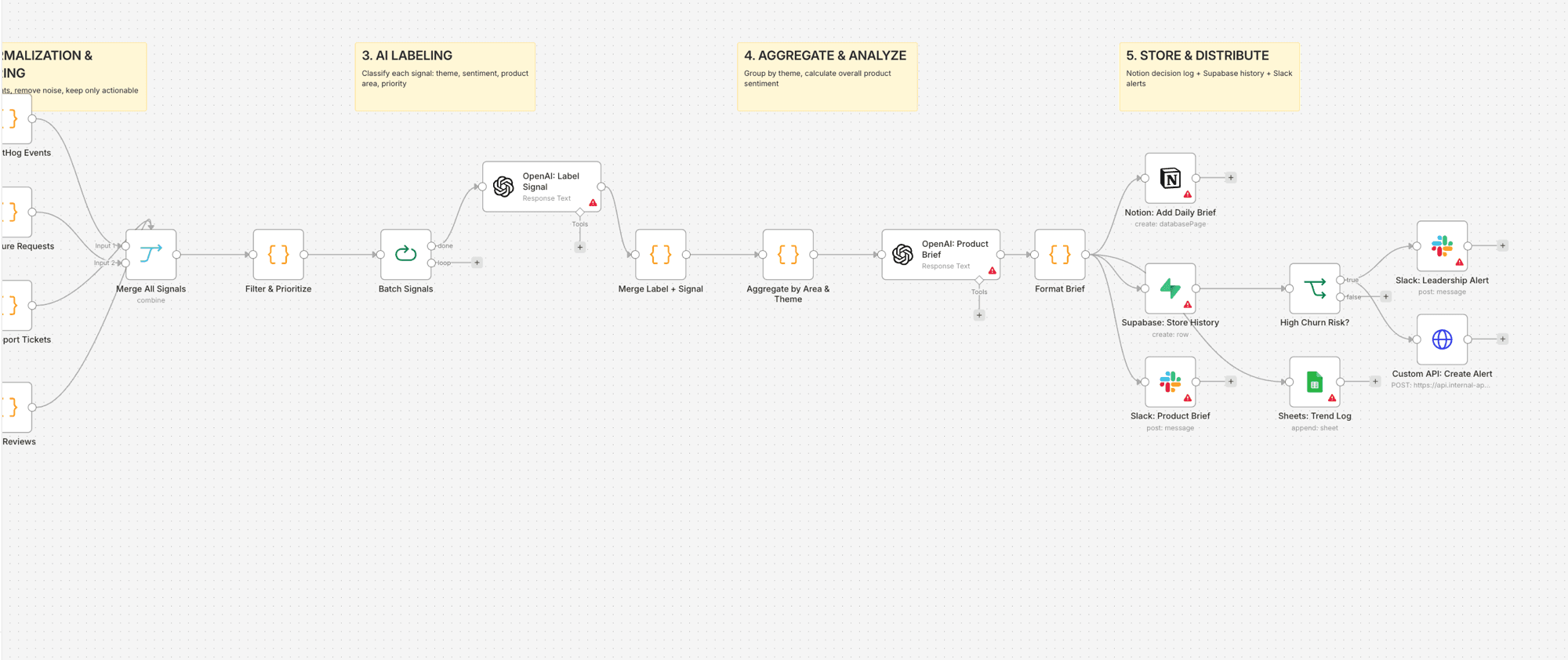
Un pipeline quotidien qui extrait les signaux des 4 sources, les normalise dans un schéma unifié, élimine le bruit, labellise chaque signal avec l'AI (périmètre produit, sentiment, impact business), agrège les tendances et génère un brief produit pour la direction envoyé dans Notion, Slack et Supabase pour le suivi historique.
- Cron quotidien à 7h (avant le standup de l'équipe produit)
- 4 extractions parallèles : événements produit PostHog, feature requests via API, tickets de support Supabase, avis App Store Supabase
- 4 nodes Code normalisent chaque source dans un format de signal unifié (source, type, user_plan, contenu, timestamp)
- Merge combine tous les signaux dans un flux unique
- Le node Filter supprime le bruit (données de test, spam, rage clicks des plans gratuits) et priorise par niveau de plan
- Split in Batches envoie des groupes de 5 à OpenAI pour labellisation : product_area, sentiment, signal_type, business_impact, priority_score, one_line_insight
- Le node Aggregate groupe par périmètre produit et thème, calcule le sentiment par zone et identifie la zone critique
- Un second appel à OpenAI génère un brief prêt à l'emploi : santé globale, top 3 des priorités, opportunités d'upsell, risques de churn
- Notion crée une page de brief quotidien dans la base de données des signaux produit
- Supabase stocke l'analyse complète pour l'historique des tendances
- Slack publie le brief dans #product-signals
- Si le risque de churn dépasse le seuil : alerte leadership + création d'une alerte interne via API
- Google Sheets enregistre les stats quotidiennes pour la visualisation des tendances
Pourquoi j'ai conçu le workflow ainsi
Les nodes Supabase extraient les données de deux tables distinctes (support_tickets et app_reviews) plutôt que d'une table combinée. Cela reflète la réalité de la création des données : les tickets viennent du système de support, les avis viennent d'un scraper App Store. Les forcer dans une seule table nécessiterait un pipeline ETL séparé et ajouterait une dépendance. En lisant directement les tables sources, le workflow dispose toujours des données les plus fraîches sans latence intermédiaire.
L'appel à l'API personnalisée pour les feature requests existe car ce client a développé son propre outil de vote interne (courant en SaaS mid-stage). J'aurais pu leur demander de migrer vers un outil tiers avec intégration n8n native, mais s'adapter au stack existant du client est le meilleur choix. Le node HTTP Request gère n'importe quelle API REST, ce qui signifie que ce workflow n'impose aucun changement d'outil à l'équipe.
Je filtre avant la labellisation (et non après) pour une raison précise. La classification par AI coûte du temps et de l'argent. Faire tourner OpenAI sur 200 signaux bruts incluant des données de test et du bruit de plans gratuits serait du gaspillage. L'étape de filtrage réduit généralement 200 éléments bruts à environ 50 signaux exploitables, réduisant le coût de l'AI de 75% tout en améliorant la qualité de la classification (moins de bruit signifie des prompts plus ciblés).
La pondération des priorités par niveau de plan est une décision business consciente. Un client enterprise qui rencontre une erreur mérite plus d'attention qu'un utilisateur gratuit qui fait des rage clicks. Il ne s'agit pas d'ignorer les utilisateurs gratuits. Il s'agit de faire en sorte que le brief produit reflète la réalité business. Quand le PM lit « 3 clients enterprise ont rencontré des erreurs d'auth sur la page intégrations », il sait qu'il s'agit d'un problème à 15k$/mois, pas d'un correctif secondaire.
Deux appels à OpenAI servent des objectifs différents. Le premier (labellisation) tourne à une température de 0.15 car nous avons besoin d'une classification structurée et déterministe. Le second (génération du brief) tourne à 0.4 car nous voulons que l'AI synthétise les tendances et fasse des recommandations. Mélanger ces deux objectifs dans un seul prompt dégrade les résultats : vous obtenez des labels moins précis ET des briefs moins pertinents.
Le workflow
Ceci est une réplique assainie du workflow de production. Les identifiants, clés API et données spécifiques au client ont été supprimés pour garantir la confidentialité.
Résultats
- L'équipe produit prend des décisions basées sur la donnée au quotidien plutôt que sur des intuitions hebdomadaires
- Signaux critiques (bugs enterprise, indicateurs de churn) détectés en quelques heures au lieu de quelques jours
- Les données historiques Supabase permettent l'analyse de tendances : « les plaintes sur le reporting ont triplé en 4 semaines »
- Le PM économise 45+ minutes par jour de vérification manuelle de dashboards
- La base de données Notion devient la source unique de vérité pour la priorisation produit
- La direction reçoit des alertes automatiques uniquement quand le risque de churn dépasse le seuil (zéro bruit)
Durée
2026
Stack technique
Responsabilités
- Architecture d'agrégation de données multi-sources
- Logique de filtrage et de priorisation des signaux
- Pipeline de labellisation par AI (sentiment, thème, périmètre produit)
- Génération automatisée de briefs produit pour la direction