The Problem
A product team makes decisions based on gut feeling because their data lives in 4 disconnected systems. PostHog tracks product events (rage clicks, feature requests, error encounters). Supabase stores support tickets and app store reviews. A custom internal API holds the feature request backlog with vote counts. Nobody synthesizes these signals into a coherent picture.
The PM opens 4 tabs every morning, scrolls through raw data, and tries to spot patterns. They miss the signal that 3 enterprise users hit the same error on the same page yesterday. They don't notice that "reporting" complaints spiked 400% this week. Without structured analysis, the loudest customer wins prioritization, not the most impactful problem.
The Solution
A daily pipeline that pulls signals from all 4 sources, normalizes them into a unified schema, filters out noise, labels each signal with AI (product area, sentiment, business impact), aggregates patterns, and generates a VP-level product brief that goes to Notion, Slack, and Supabase for historical trending.
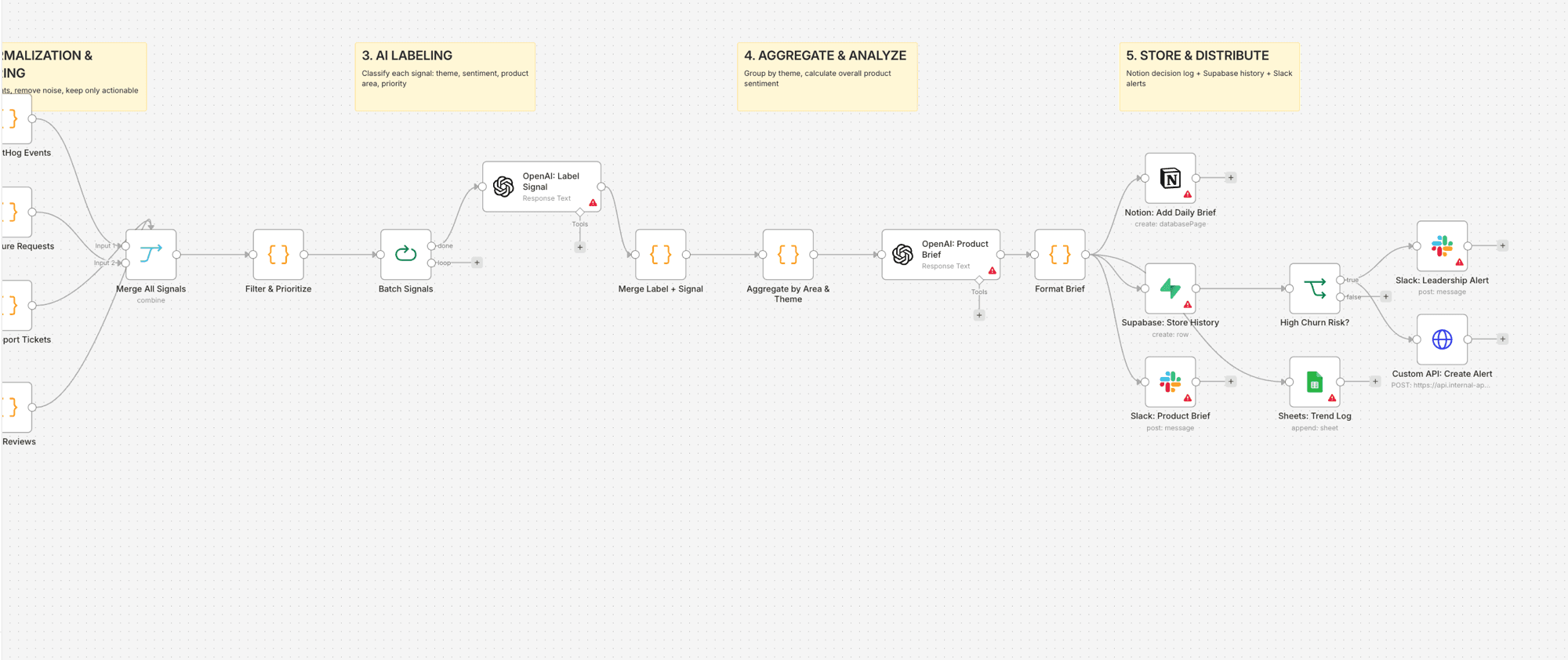
- Daily cron fires at 7am (before the product team's standup)
- 4 parallel pulls: PostHog product events, Custom API feature requests, Supabase support tickets, Supabase app store reviews
- 4 Code nodes normalize each source into a unified signal format (source, type, user_plan, content, timestamp)
- Merge combines all signals into a single stream
- Filter node removes noise (test data, spam, free-plan rage clicks) and prioritizes by plan tier
- Split in Batches sends groups of 5 to OpenAI for labeling: product_area, sentiment, signal_type, business_impact, priority_score, one_line_insight
- Aggregate node groups by product area and theme, calculates sentiment per area, identifies the critical zone
- Second OpenAI call generates a decision-ready brief: overall health, top 3 priorities, expansion opportunities, churn risks
- Notion creates a daily brief page in the product signals database
- Supabase stores the full analysis for historical trending
- Slack posts the brief to #product-signals
- If churn risk count exceeds threshold: leadership alert + custom API creates an internal alert
- Google Sheets logs daily stats for trend visualization
Why I Built It This Way
The Supabase nodes pull from two separate tables (support_tickets and app_reviews) rather than one combined table. This reflects how data actually gets created: tickets come from the support system, reviews come from an App Store scraper. Forcing them into one table would require a separate ETL pipeline and add a dependency. By reading from source tables directly, the workflow always has the freshest data with no intermediary lag.
The Custom API call for feature requests exists because this client built their own internal feature voting tool (common in mid-stage SaaS). I could have asked them to migrate to a third-party tool with native n8n integration, but adapting to the client's existing stack is the right call. The HTTP Request node handles any REST API, which means this workflow doesn't force tool changes on the team.
I filter before labeling (not after) for a deliberate reason. AI classification costs money and time. Running OpenAI on 200 raw signals including test data and free-plan noise would be wasteful. The filter step typically reduces 200 raw items to ~50 actionable signals, cutting the AI cost by 75% while improving classification quality (less noise means more focused prompts).
The priority weighting by plan tier is a conscious business decision. An enterprise customer hitting an error is worth more attention than a free user rage-clicking. This isn't about ignoring free users. It's about making the product brief reflect business reality. When the PM reads "3 enterprise users hit auth errors on the integrations page", they know that's a $15k/month problem, not a "nice to fix eventually" problem.
Two OpenAI calls serve different purposes. The first (labeling) runs at temperature 0.15 because we need deterministic, structured classification. The second (brief generation) runs at 0.4 because we want the AI to synthesize patterns and make recommendations. Mixing these in one prompt degrades both: you get less accurate labels AND less insightful briefs.
The Workflow
This is a sanitized replica of the production workflow. Credentials, API keys, and client-specific data have been removed to protect confidentiality.
Results
- Product team makes data-backed decisions daily instead of weekly gut checks
- Critical signals (enterprise bugs, churn indicators) surfaced within hours instead of days
- Historical Supabase data enables trend analysis: "reporting complaints grew 3x over 4 weeks"
- PM saves 45+ minutes/day of manual dashboard checking
- Notion database becomes the single source of truth for product prioritization
- Leadership gets automatic alerts only when churn risk exceeds threshold (no noise)
Timeline
2026
Stack
Responsibilities
- Multi-source data aggregation architecture
- Signal filtering and prioritization logic
- AI labeling pipeline (sentiment, theme, product area)
- Automated VP-level product brief generation