Le problème
Une startup SaaS de 30 personnes collecte du feedback sur 4 canaux : conversations Intercom, sondages NPS (Typeform), une boîte mail support et un canal Slack #product-feedback où l'équipe poste les retours clients. Le PM vérifie chaque source manuellement, environ une fois par semaine. Les tendances passent inaperçues. Les signaux urgents sont enterrés. Le PM passe plus de 3 heures chaque lundi à tout lire sans aucune analyse structurée.
Le pire : quand un client mentionne un signal de churn potentiel ("nous évaluons des alternatives", "ce produit ne répond plus à nos besoins"), le message reste sans réponse dans Intercom pendant des jours. Quand quelqu'un s'en aperçoit, le client est déjà parti. Le feedback existe, mais personne ne le surveille systématiquement.
La solution
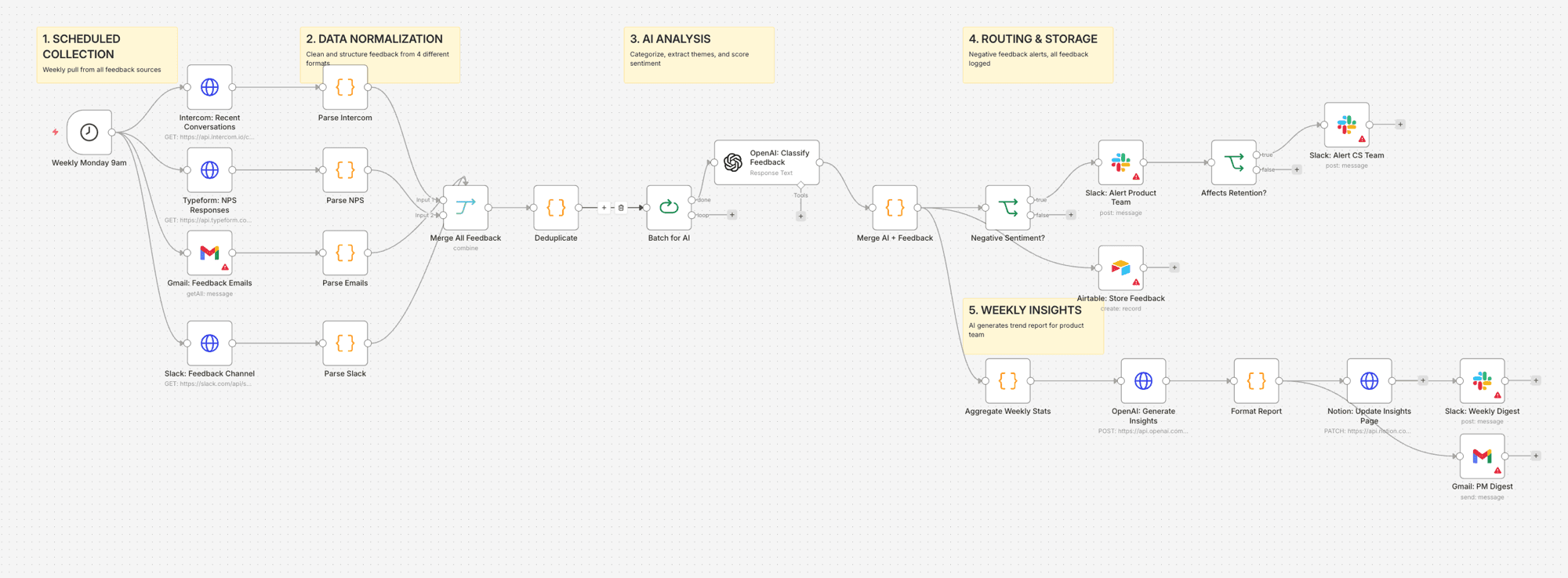
Un pipeline de 30 nodes qui s'exécute chaque lundi à 9h. Il récupère les 7 derniers jours de feedback depuis les 4 sources, normalise les données dans un format unifié, exécute une classification AI sur chaque élément (catégorie, sentiment, urgence, thème), route les feedbacks négatifs et les risques de churn vers les bonnes équipes immédiatement, et génère un rapport d'insights hebdomadaire envoyé dans Notion, Slack et la boîte mail du PM.
- Le Schedule trigger se lance le lundi à 9h
- 4 requêtes HTTP parallèles interrogent les API Intercom, Typeform, Gmail et Slack
- 4 nodes Code normalisent chaque source vers un schéma unifié (source, date, client, email, contenu)
- Le node Merge combine tous les feedbacks dans un flux unique
- La déduplication supprime les contenus postés en double (même feedback dans Slack + email)
- Le node Split in Batches envoie des groupes de 5 à OpenAI pour classification (catégorie, sentiment -1 à 1, urgence, thème, impact sur la rétention)
- Chaque élément est stocké dans Airtable avec ses métadonnées AI
- Les éléments à sentiment négatif (< -0.3) déclenchent une alerte Slack immédiate dans #product-alerts
- Les éléments affectant la rétention alertent aussi la #cs-team pour un suivi humain sous 24h
- Le node Aggregate calcule les stats hebdomadaires (fréquence des thèmes, tendance de sentiment, distribution par catégorie)
- OpenAI génère un rapport de 5-7 points clés avec les tendances émergentes et les actions recommandées
- Le rapport est envoyé dans Notion (page roadmap produit), Slack (#product-team) et par email (digest pour le PM)
Pourquoi j'ai conçu le workflow ainsi
J'utilise des nodes HTTP Request pour Intercom, Typeform, Gmail et Slack plutôt que les nodes natifs car chaque API nécessite des filtres spécifiques que les nodes natifs ne permettent pas. Le node natif Intercom ne permet pas de filtrer par plage de dates. Celui de Typeform ne supporte pas le paramètre `since`. Pour ce cas précis, le HTTP brut donne un contrôle total sur les données récupérées, réduisant le bruit et les coûts d'API.
La couche de normalisation (4 nodes Code séparés) est nécessaire car chaque source a des structures de données très différentes. Intercom imbrique les contacts dans les conversations. Typeform utilise des références de champs. Gmail utilise des headers. Gérer ces 4 formats dans un seul node Code serait ingérable. Un parser par source permet d'ajouter une 5ème source sans toucher à la logique existante.
Je traite les appels AI par lots de 5 plutôt qu'un par un ou tous d'un coup. Un par un signifie 50+ appels API (lent, coûteux). Tous d'un coup signifie un prompt massif qu'OpenAI gère mal (contexte trop long, baisse de qualité). Les lots de 5 sont le compromis idéal : rapide (~6 lots pour 30 items), économique, et chaque appel a un contexte ciblé pour une précision maximale.
Le système de double alerte (équipe produit pour le négatif + CS team pour la rétention) est critique. Tout feedback négatif ne signifie pas un churn imminent. Un client disant "cette feature est frustrante" a besoin d'un correctif produit. Un client disant "nous regardons ailleurs" a besoin d'un contact humain immédiat. L'AI distingue ces cas avec le booléen `affects_retention`, qui déclenche un chemin de réponse différent.
Le rapport d'insights hebdomadaire utilise un processus en deux étapes : d'abord agréger les stats par code (chiffres exacts, pourcentages), puis passer ces stats à OpenAI pour l'interprétation. Je ne demande jamais à l'AI de compter ou de calculer des pourcentages. L'AI est mauvaise en maths. Le node Code gère les chiffres, l'AI gère l'interprétation. C'est un principe fondamental de mon architecture.
Le workflow
Ceci est une version nettoyée du workflow de production. Les identifiants, clés API et données clients ont été supprimés pour garantir la confidentialité.
Résultats
- Le PM gagne 3+ heures/semaine sur la revue manuelle des feedbacks
- Signaux de risque de churn détectés le jour même au lieu de la semaine suivante (ou jamais)
- L'équipe produit reçoit des insights structurés et actionnables au lieu de bruit brut
- 2 churns évités dès le premier mois grâce au suivi CS immédiat sur les feedbacks flaggés
- Base de données de feedback complète et interrogeable dans Airtable avec métadonnées AI
- Page roadmap Notion toujours à jour avec des insights basés sur des données réelles pour les discussions de priorisation
Durée
2026
Stack technique
Responsabilités
- Architecture d'agrégation de données multi-sources
- Catégorisation et analyse de sentiment par AI
- Détection des risques de churn via les signaux de feedback
- Pipeline automatisé de génération d'insights hebdomadaires