Context
A cloud-hosted RAG system that indexes tool documentation into a vector database, then exposes it to Claude Code via MCP so the model always works from the latest docs instead of relying on stale training data. All the team is working on a reliable and clean documentation tailored for the dev version of the project.
The Problem
Claude Code's training data can be months behind. When you're using a fast-moving SDK (Gemini, RevenueCat, Firebase, Expo), the model hallucinates outdated APIs, deprecated parameters, or patterns that no longer work. The alternative, pasting full docs into context, didn't scale well with a 200k context window at that time (i've created this tool around September 2025), and services like Context7 often returned poorly parsed or uncleaned documentation that confused the model more than it helped.
I needed a way to feed Claude Code clean, chunked, searchable documentation that I controlled, indexed the way I wanted, from sources I trusted.
What I Built
A three-part system: a web UI for uploading docs, a FastAPI backend that chunks and embeds them into ChromaDB, and an MCP server that Claude Code connects to for semantic search.
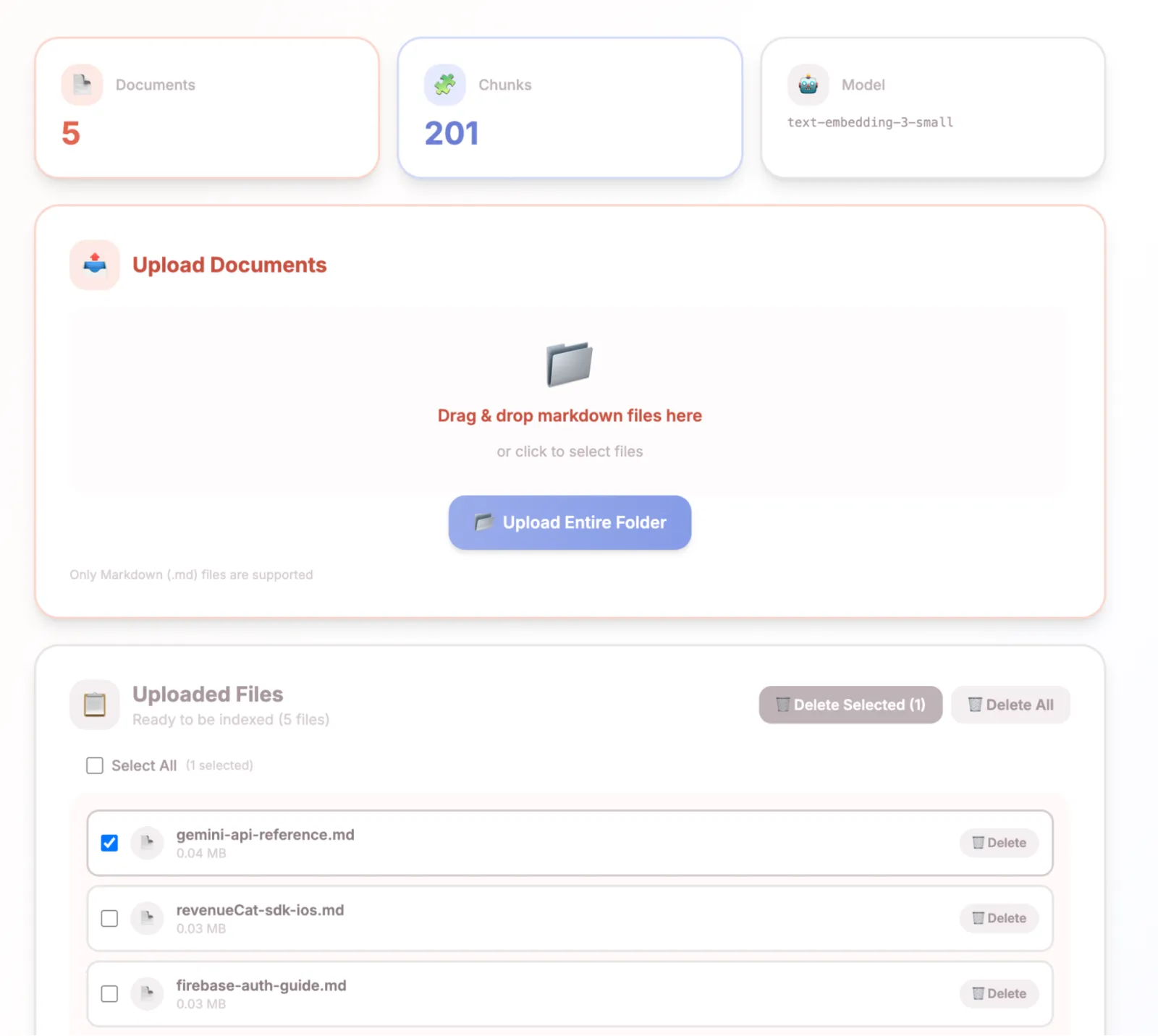
Upload & Index: Drop markdown files into the web UI (Next.js). The backend processes them with header-aware semantic chunking, generates embeddings via OpenAI's text-embedding-3-small, and stores vectors in ChromaDB Cloud.
Search via MCP: Claude Code connects to the MCP server over SSE (Server-Sent Events). When it needs documentation context, it queries the vector database and gets back the most relevant chunks with source file and section metadata.
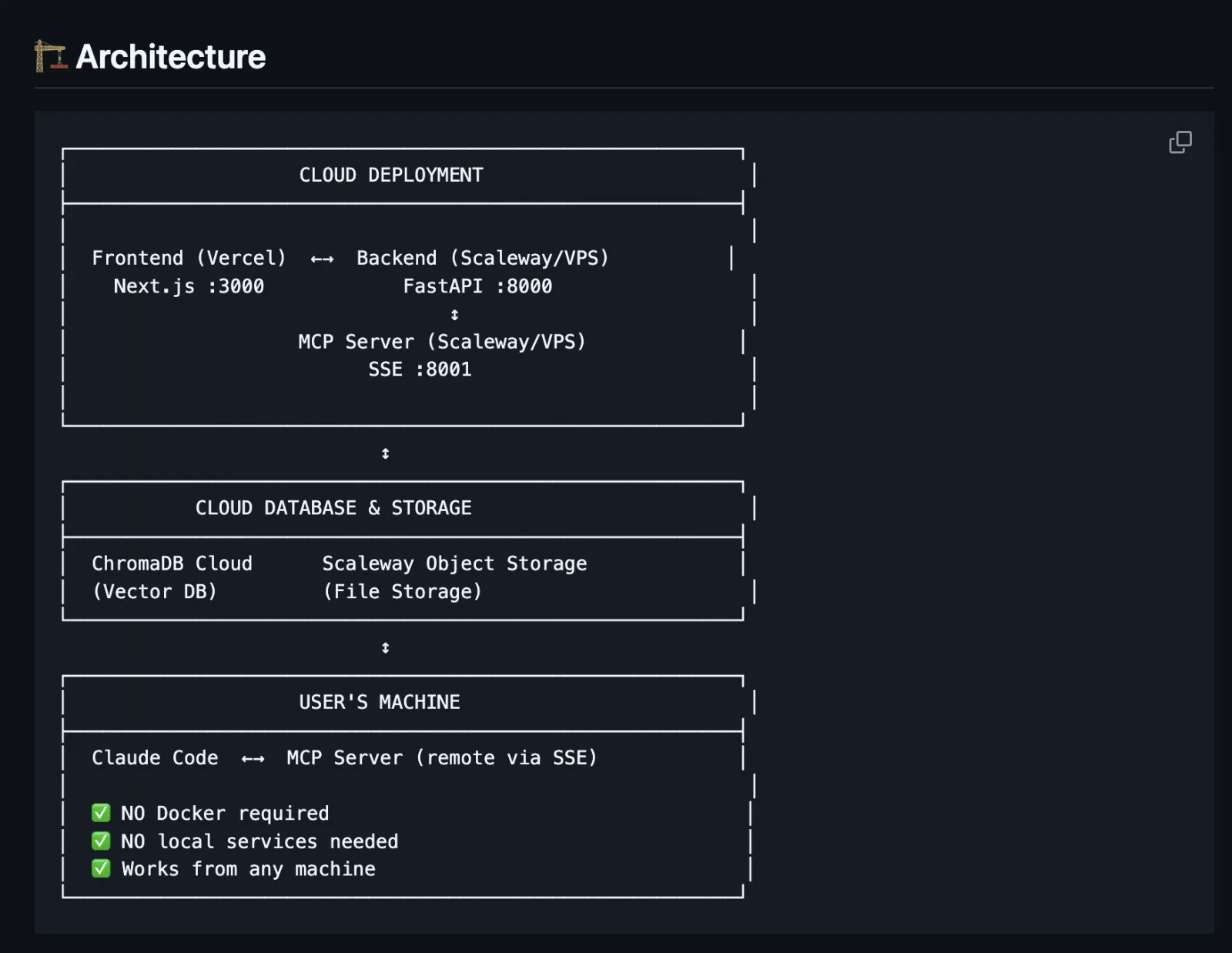
Cloud-native, no local setup: ChromaDB Cloud for vectors, Scaleway Object Storage for files, Vercel for the frontend, a small VPS for the backend. Users just add one SSE URL to their Claude Code config, no Docker, no local services. I wanted something very simple.
Why Not Just Use Context7 or Paste Docs?
- Control over parsing: I clean and structure docs specifically for LLM consumption, no navigation HTML, no broken code blocks, no irrelevant changelog entries or images AI cannot read.
- Semantic search > full dump: With RAG, Claude gets only the relevant 3-5 chunks instead of 50 pages of docs eating context
- Version based: I used the documentation based on the version we use. That could sound like a maintenance burden, but I'm sure it's possible to push the system and tie it to automatic cleaning of a new doc based on the version the repo is using.
- Works from anywhere: SSE transport means any machine with Claude Code can connect
This project was really simple to do and helped improve the overall code quality. We didn't use it for smaller projects, but I'm sure this kind of project is a nice guardrails to add to an LLM.
Timeline
Sep 2025
Stack
Responsibilities
- RAG pipeline design and implementation
- MCP server development (SSE transport)
- Semantic chunking strategy
- Cloud infrastructure (ChromaDB, Scaleway, Vercel)