Contexte
Un système RAG hébergé dans le cloud qui indexe la documentation des outils dans une base de données vectorielle, puis l'expose à Claude Code via MCP. Ainsi, le modèle travaille toujours avec la documentation la plus récente au lieu de se fier à des données d'entraînement obsolètes. Toute l'équipe travaille sur une documentation fiable et propre, adaptée à la version de développement du projet.
Le problème
Les données d'entraînement de Claude Code peuvent avoir des mois de retard. Quand on utilise un SDK qui évolue vite (Gemini, RevenueCat, Firebase, Expo), le modèle hallucine des API obsolètes, des paramètres dépréciés ou des patterns qui ne fonctionnent plus. L'alternative, qui consiste à coller toute la documentation dans le contexte, n'était pas viable à grande échelle avec une fenêtre de contexte de 200k à l'époque (j'ai créé cet outil vers septembre 2025). De plus, des services comme Context7 renvoyaient souvent une documentation mal parsée ou non nettoyée, ce qui perturbait le modèle plus que ça ne l'aidait.
J'avais besoin d'un moyen de fournir à Claude Code une documentation propre, découpée en chunks, interrogeable, que je pouvais contrôler et indexer comme je le souhaitais, à partir de sources de confiance.
Ce que j'ai construit
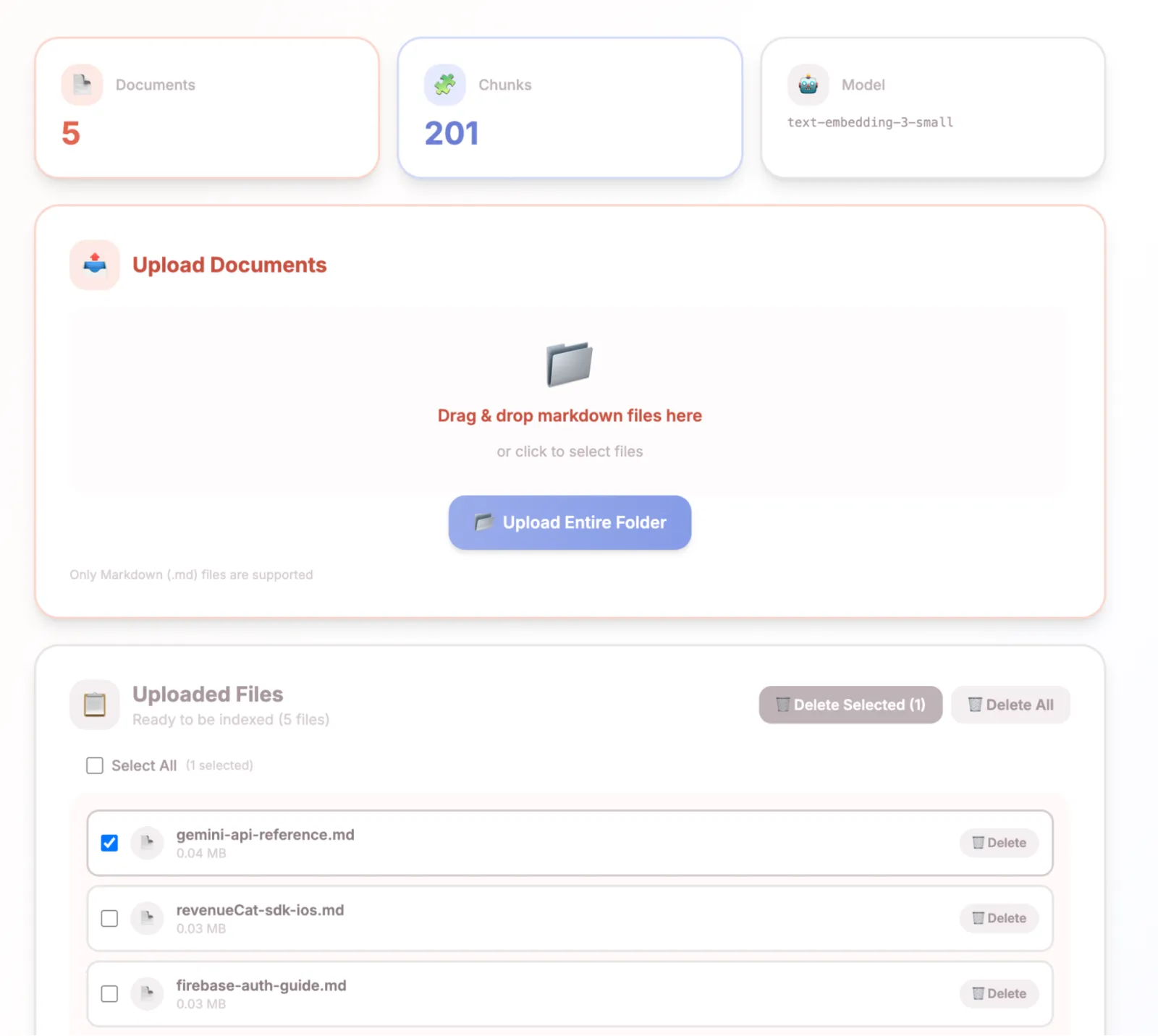
Un système en trois parties : une interface web pour uploader la documentation, un backend FastAPI qui la découpe en chunks et génère les embeddings dans ChromaDB, et un serveur MCP auquel Claude Code se connecte pour la recherche sémantique.
Upload et indexation : on glisse des fichiers markdown dans l'interface web (Next.js). Le backend les traite avec un chunking sémantique qui prend en compte les titres, génère les embeddings via text-embedding-3-small d'OpenAI, et stocke les vecteurs dans ChromaDB Cloud.
Recherche via MCP : Claude Code se connecte au serveur MCP via SSE (Server-Sent Events). Quand il a besoin de contexte sur la documentation, il interroge la base de données vectorielle et récupère les chunks les plus pertinents avec les métadonnées du fichier source et de la section.
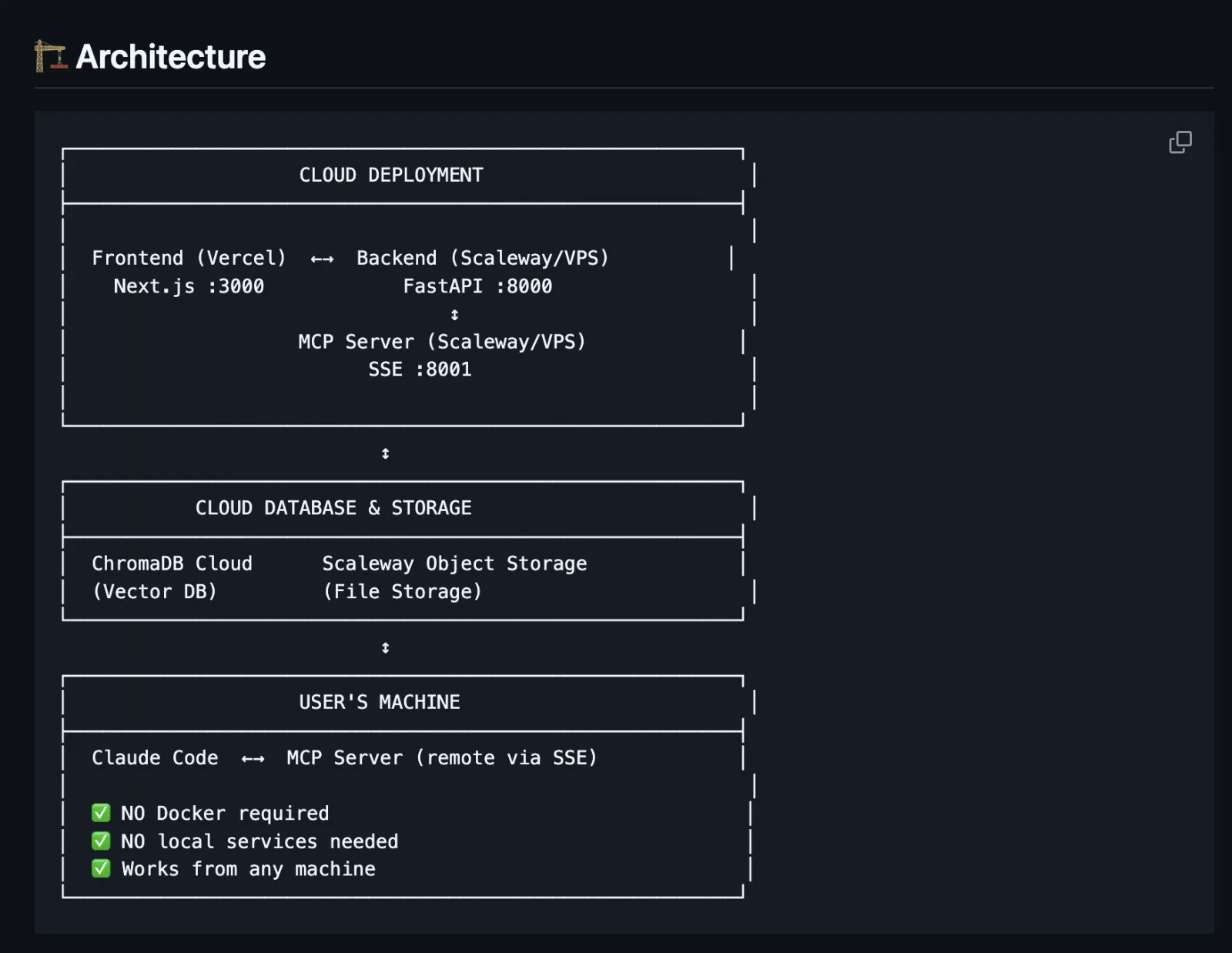
Cloud-native, aucune configuration locale : ChromaDB Cloud pour les vecteurs, Scaleway Object Storage pour les fichiers, Vercel pour le frontend, un petit VPS pour le backend. Les utilisateurs ajoutent simplement une URL SSE à leur configuration Claude Code, sans Docker ni services locaux. Je voulais quelque chose de très simple.
Pourquoi ne pas utiliser Context7 ou coller la documentation ?
- Contrôle sur le parsing : je nettoie et structure la documentation spécifiquement pour être consommée par un LLM. Pas de HTML de navigation, pas de blocs de code cassés, pas d'entrées de changelog inutiles ou d'images que l'IA ne peut pas lire.
- Recherche sémantique > dump complet : avec le RAG, Claude ne reçoit que les 3 à 5 chunks pertinents au lieu de 50 pages de documentation qui saturent le contexte.
- Basé sur la version : j'ai utilisé la documentation correspondant à la version que nous utilisons. Cela peut sembler lourd à maintenir, mais je suis convaincu qu'il est possible de pousser le système et de le lier à un nettoyage automatique d'une nouvelle documentation en fonction de la version utilisée par le repo.
- Fonctionne de n'importe où : le transport SSE permet à n'importe quelle machine équipée de Claude Code de se connecter.
Ce projet était vraiment simple à réaliser et a permis d'améliorer la qualité globale du code. Nous ne l'avons pas utilisé pour de plus petits projets, mais je suis certain que ce type de projet constitue d'excellents garde-fous à ajouter à un LLM.
Durée
Sep 2025
Stack technique
Responsabilités
- Conception et implémentation du pipeline RAG
- Développement du serveur MCP (transport SSE)
- Stratégie de chunking sémantique
- Infrastructure cloud (ChromaDB, Scaleway, Vercel)